After reading this article you’ll know how to:
-
How to set up a smart collection search in your application
-
Enable splitting large documents into paragraphs
-
Use the query generator step to manipulate data
Extending the AI functionality across the platform, Betty Blocks offers another set of tools made for working with text - AI Search. After installing the block in your application, you will be able to employ three important action steps: collection search, query generator, and chunk to build helpful applications powered by OpenAI.
What can we build using these action steps?
Using the capabilities provided to us by ChatGPT, we can accomplish multiple tasks with text: translation, classification, summarization & anonymization, question-answering, and so on. Here, we will explain the collection search, query generation, and result chunking - three action steps provided to the Betty Blocks users in a single AI Search block. But what exactly do they offer us? What can these functions be applied to? Let's delve into some theory to ensure you have a clear understanding.
-
Collection search is applied to search through a large collection of data. For example, if you're building a news aggregation app, you can use the collection search to find articles that match a user's interests. The output, an array of objects with fields like id, text, and score, can be used to rank the search results.
-
Query generator can be used to build a search engine that understands natural language queries. For instance, if you're building a customer support portal, you can use the query generator to extract keywords from customer queries. This way, even if a customer types in a question like "How do I reset my password?", the query generator can identify "reset" and "password" as the key terms and use them to search your knowledge base.
-
Chunk breaks down large pieces of text into smaller, more manageable chunks. For example, if you're building a plagiarism detection tool, you can use the chunk function to break down a document into smaller pieces and then compare each piece with a database of known works.
Use case explained
In our use case, we will be building an application that can search through a large collection of documents and provide a comprehensive answer to a user's query. This solution could be used in a variety of contexts, from customer support to academic research.
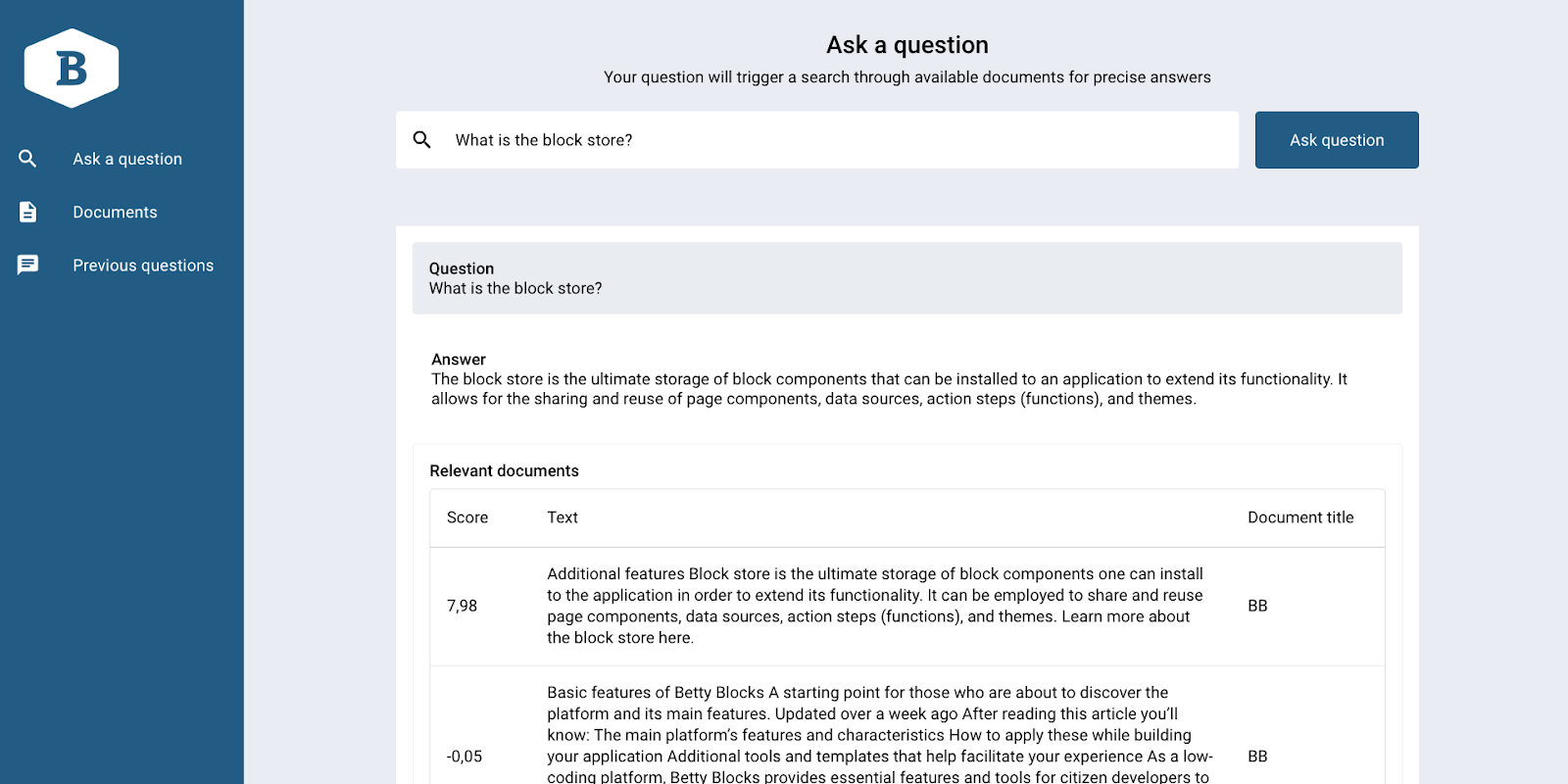
As per using the steps, it will follow the next scenario:
-
The application allows users to upload documents, which are then automatically converted into text. The text is then divided into smaller chunks using the chunk action step, making it easier to work with. These chunks are displayed in the data table, labeled as 'Relevant documents', and ranked for simple reference.
-
The query generator then identifies keywords from the user's query, and the collection search function is used to find relevant chunks of text
-
Finally, the prompt step is used to generate a new text that combines all the relevant information into a coherent answer
Preparation
Once you’ve installed the AI Search block into your application, you can apply any of the included action steps (functions) to create your solutions. Additionally, let’s also install the parse document to text and generative AI
Added models & properties
Before we dive into configurations on our pages and action builder, there are a few things we need to prepare within the data model. We are going to use the following models for our use case example:
-
Document to store unprocessed data. The properties are (besides the default ones):
-
‘Title’ (text, single-line)
-
‘Content’ (text, multi-line)
-
‘File’ (file)
-
-
DocumentChunk is used for storing chunks (pieces) of text:
-
‘Title’ (text, multi-line)
-
-
QuestionAnswer for input and output data:
-
‘Question’ (text, single-line)
-
‘Answer’ (text, multi-line)
-
-
SearchResult will have to contain chunks of data (text) that relate to the user query. It will additionally have the score - points of how closely a chunk matches the user query (question):
-
‘Title’ (text, multi-line)
-
‘Score’ (Number with decimals)
-
-
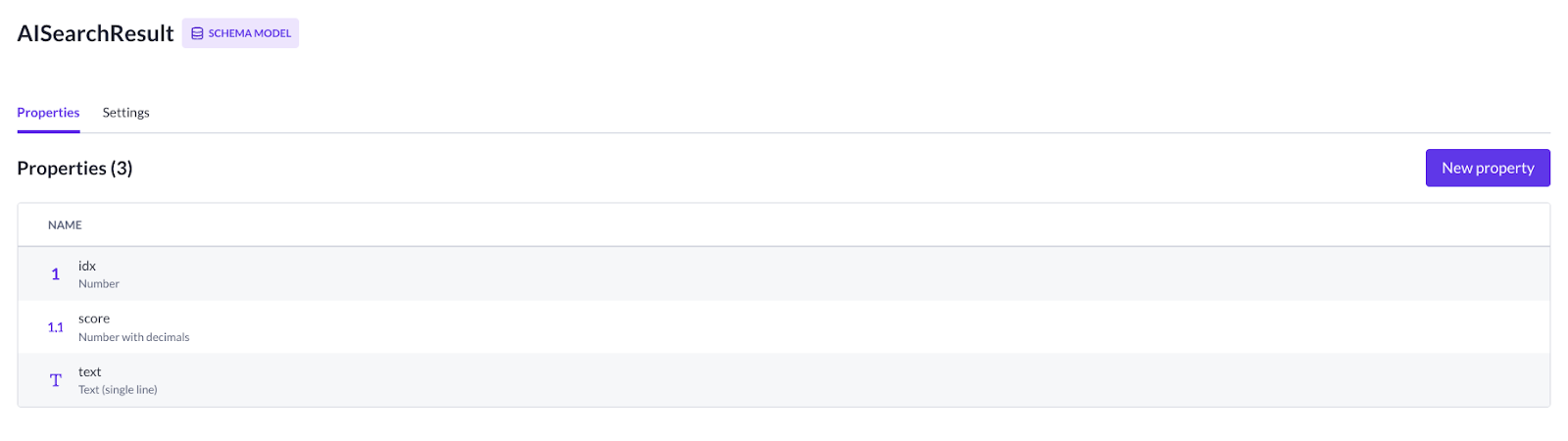
AISearchResult - a schema model that is used to store multiple AI responses:
-
‘ID’ (number)
-
‘Score’ (Number with decimals)
-
‘Text’ (text, single-line)
-
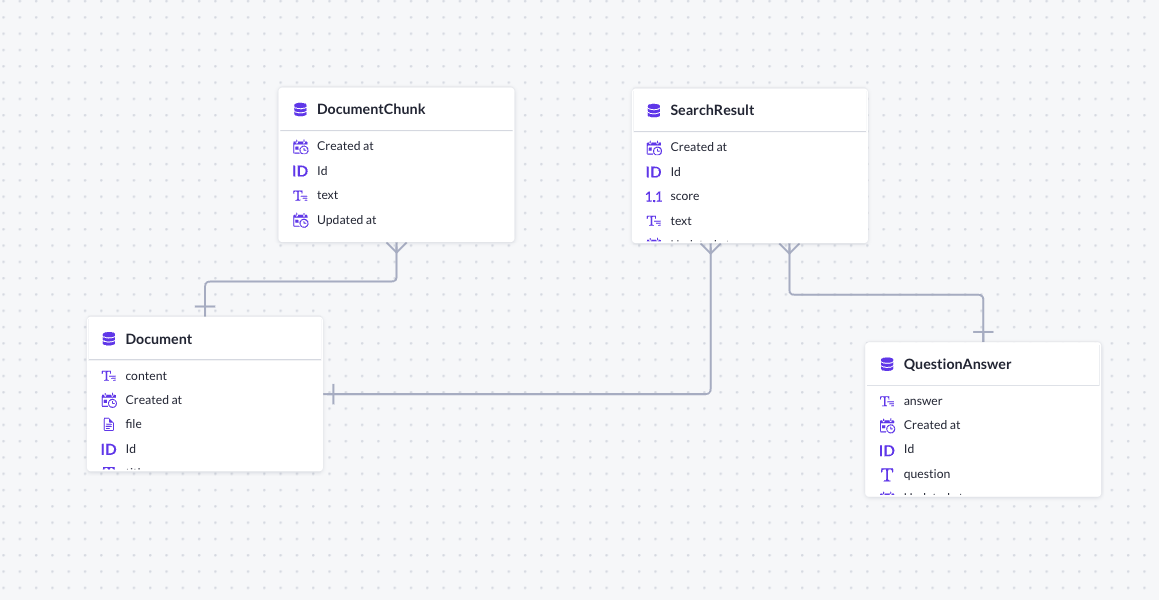
The relations between the models will look like this:
-
Many DocumentChunks belong to one Document
-
Many SearchResults belong to one Document
-
Many SearchResults belong to one QuestionAnswer
What pages do we need?
Without going into too much detail, here are the primary pages we are going to use for this use case:
-
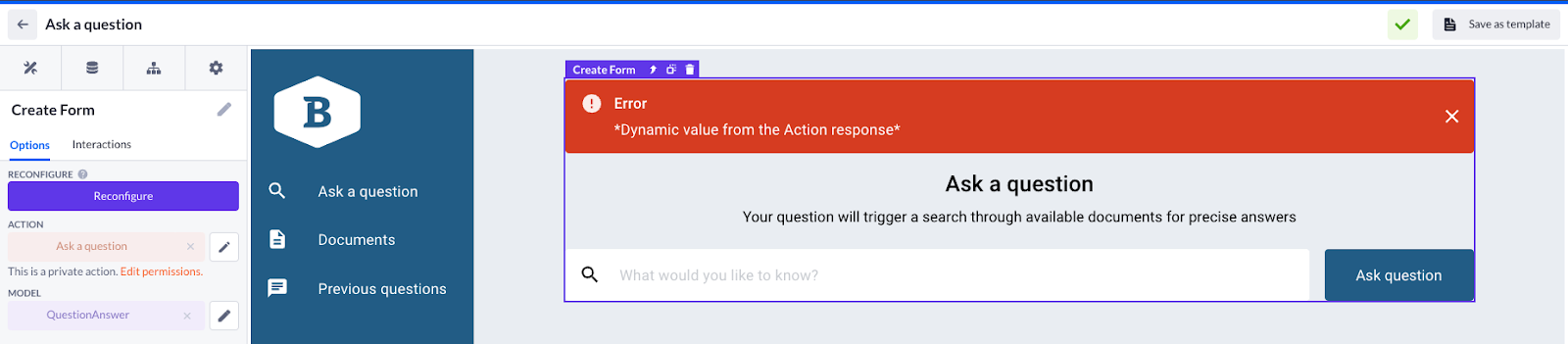
‘Ask a question’ page with a Create form, based on the QuestionAnswer model. The action behind it will be used further in the configuration
-
Below the create form, there is a data container showing the result of the query (based on the QuestionAnswer model) and the data table showing relevant documents to the search (based on the SearchResult model)

-
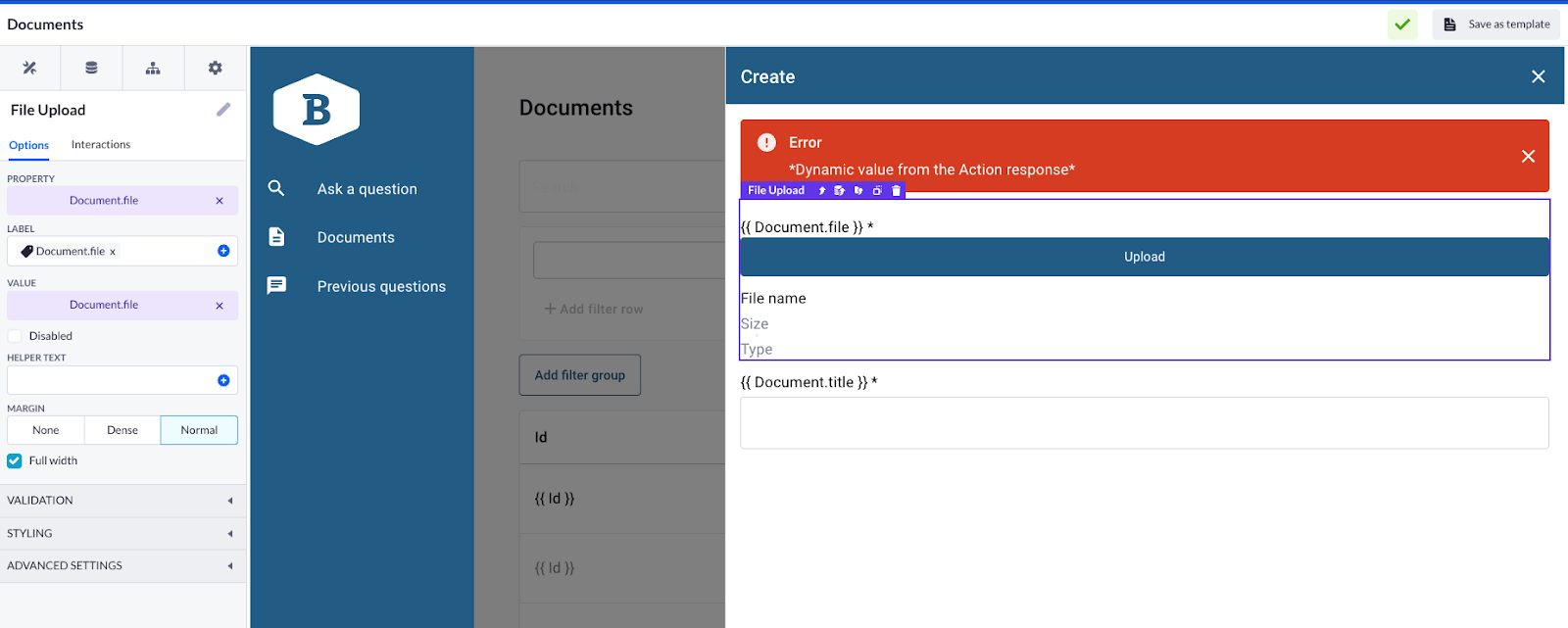
‘Documents’ page based on the Document model. It can be created using the back office template with the file upload functionality added to the create form. This way we will be able to add some data and store it
Using AI Search steps
Hopefully, you already know how this case should look from the perspective of the page builder and data model. Now let’s dive into the actions and build several flows to make things work in our application.
Chunk
The first thing we need to do is cover the text chunking functionality. While creating this AI search flow, you have to split the texts into smaller pieces, so that they are shown in the data table as selected Relevant documents.
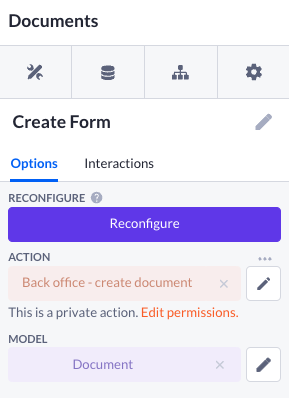
1. Open the Create document action from the Create form on the Documents page, or select it from the Actions overview.
2. Add a few text input variables to the Start step: file and title.
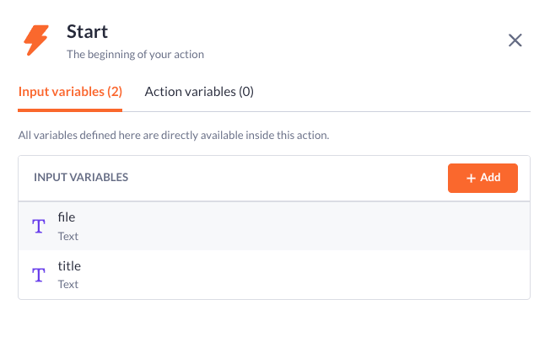
3. The first Create record step should look like this:
-
Select the Document model with the file and title properties and input variables from the previous step as their value.
-
Type in the name of the result variable.
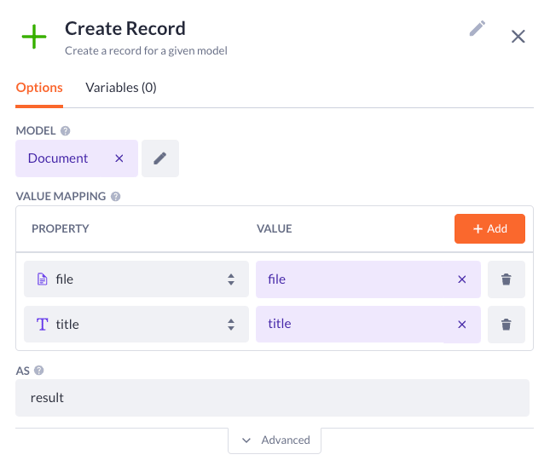
4. Drop the Parse document to text step as the next one:
-
Specify the document to be parsed: result.file in our case
-
Type in the name for the result variable
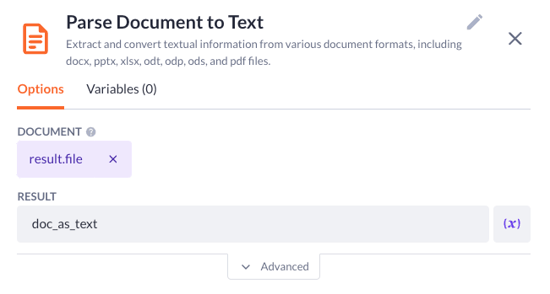
5. Now as this document is parsed to text, we can apply the update record step:
-
Pick up the result variable as the record to update
-
Select the content property with the doc_as_text variable as the value
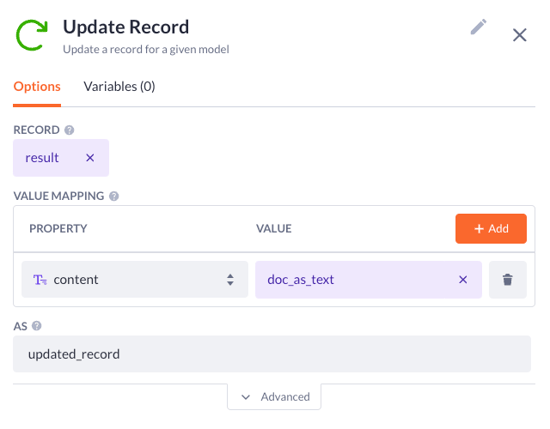
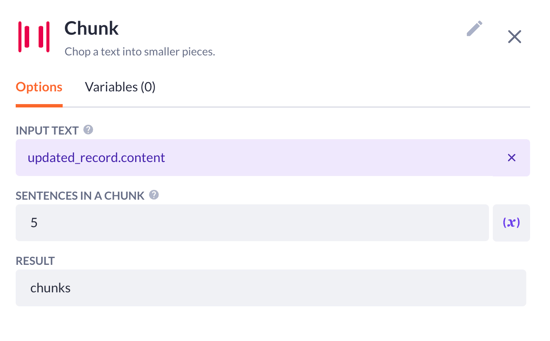
6. Time to add the chunk AI step. Here we will:
-
Pick up the updated_record variable that comes as the updated content text property from the previous steps
-
Decide on the number of sentences in a chunk you want to see
-
Type in the name for the result variable
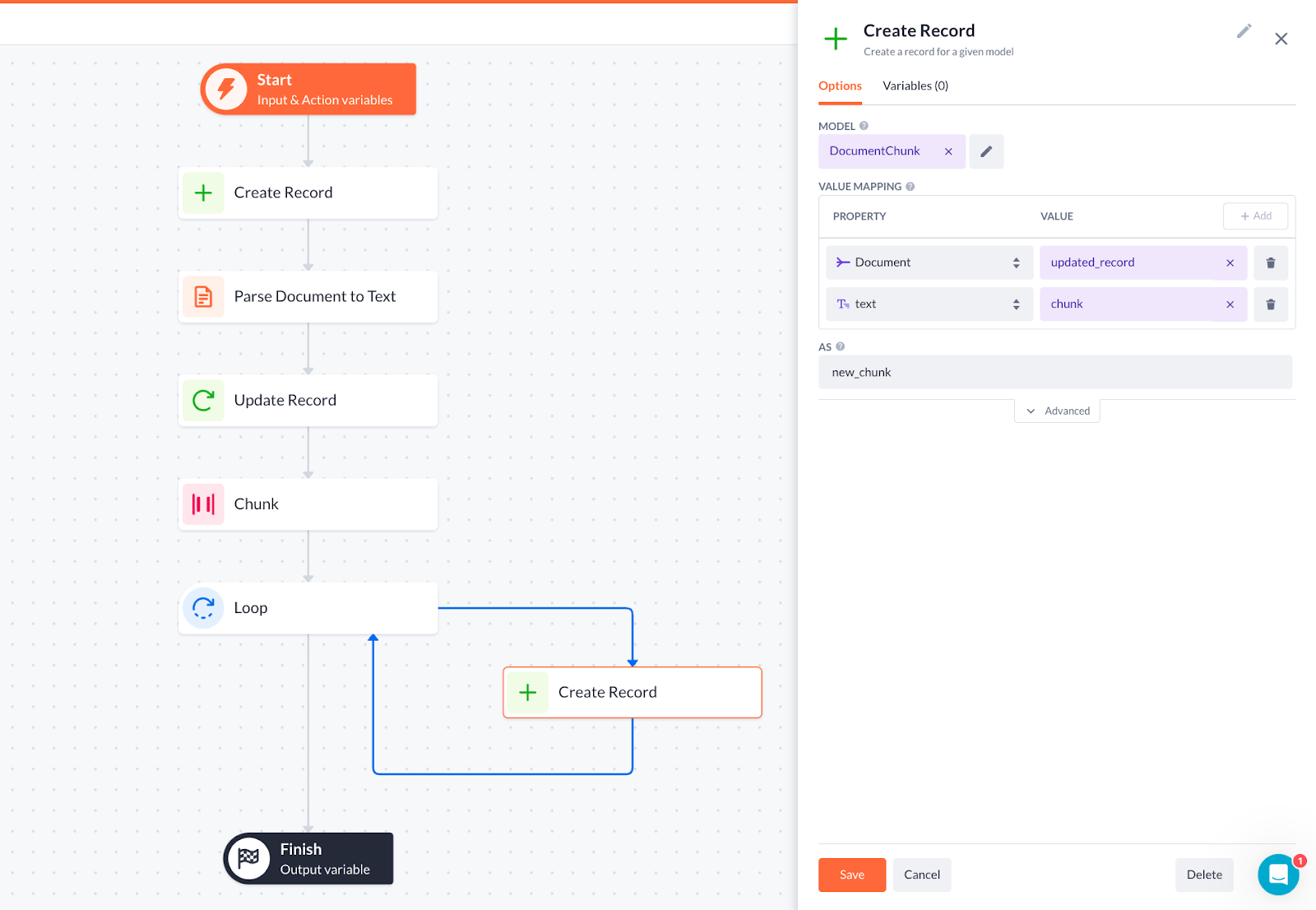
7. To finish with this action:
-
Add a Loop step with array looping through the chunks (result variable from the chunk step)
-
Drop the Create record step to the loop:
-
Select the DocumentChunk model with the Document (model related to it) and text as properties. Set the values updated_record and chunk accordingly
-
Type in the name of the result variable (as new_chunk, for example)
-
Select the result as the output variable in the Finish step.
Query generator & collection search
Let’s get to another action where we will build the ‘Ask a question’ flow. As it is our primary action within this application, therefore it will contain three AI-powered steps: query generator, collection search, and prompt. So make sure you’ve installed both Generative AI and AI Search blocks from the Block Store.
1. Begin by adding a text input variable to the Start step
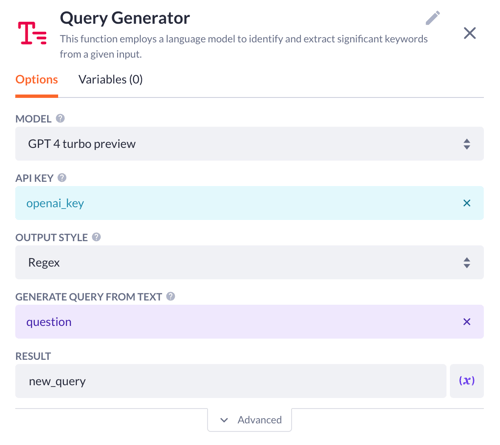
2. Then drop the query generator step. It will enable a language model to identify and extract the important keywords from a question (aka ‘query’). In the step options:
-
Choose the desired AI model: ChatGPT 4 in our case
-
Type in an API key or select it from the configurations. This key should be provided from OpenAI’s side
-
Select the output style. For now, there’s only a Regex type available that can be used with a ‘contains’ filter in your data model
-
Again, select the question variable as something the system will generate a query from
-
Type in the result variable (e.g. new_query) before saving
3. Next goes the Collection search. Here we will pick up the query and search through the chunk collection that we generated in a previous action.
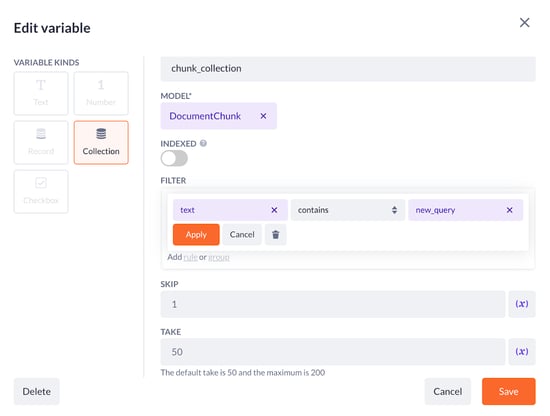
-
Go to the Variables tab and add a collection variable, let’s call it chunk_collection
-
Select the DocumentChunk model
-
Set the filter to: text contains new_query
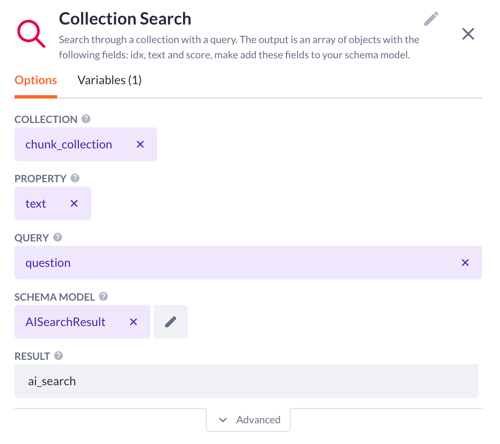
-
Come back to the Options tab. Pick the collection to search through. Ours is chunk_collection
-
Choose the text property from the DocumentChunk model
-
Query stays the same as before - question
-
Select a schema model. In our use case, that is called AISearchResult. It will be used later
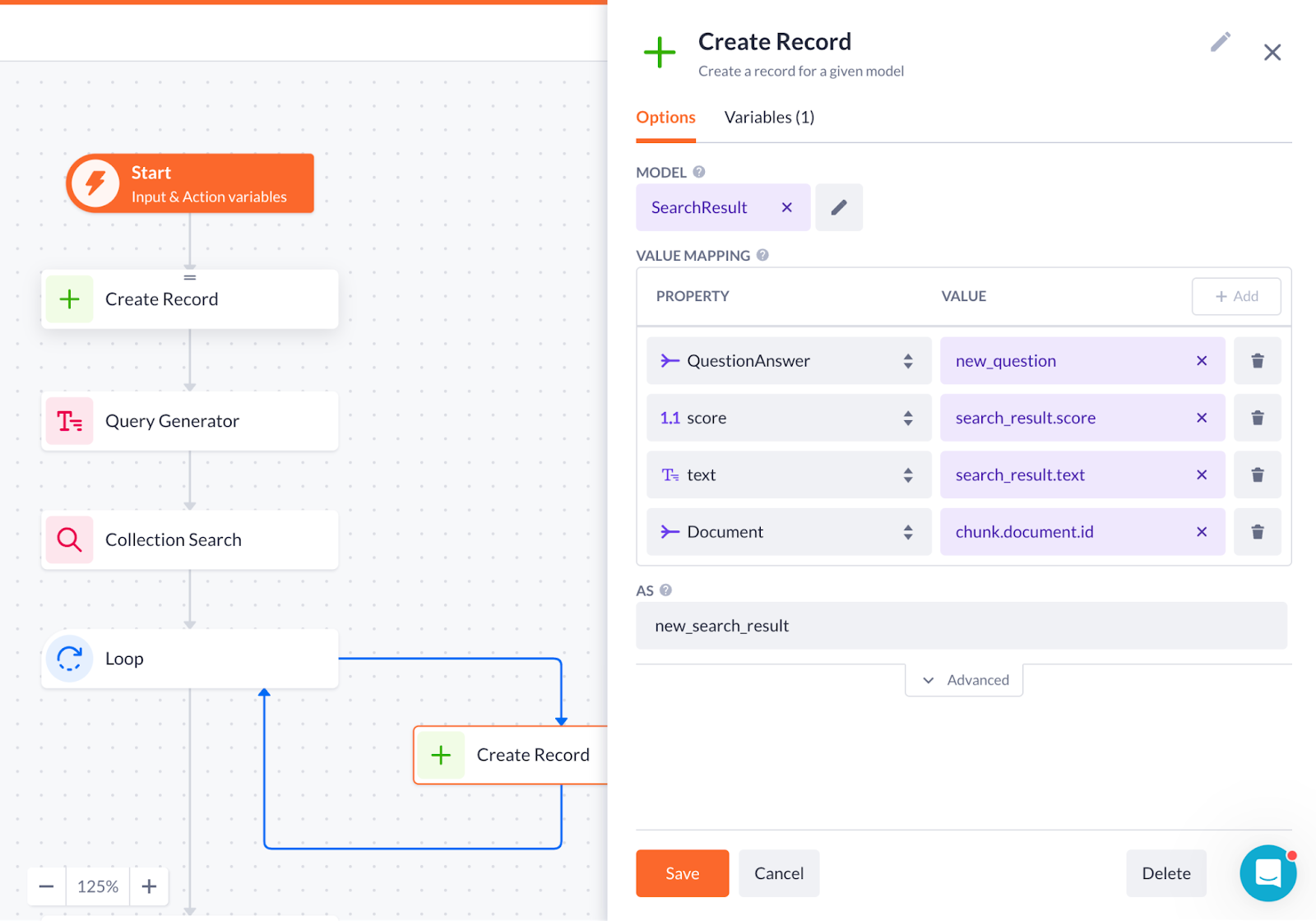
4. After you save the collection search step, proceed to the same scenario we did in the previous action setting:
-
Add a Loop step with array looping through the ai_search (result variable from the collection search step)
-
Drop the Create record step to the loop:
-
Select the SearchResult model with
-
QuestionAnswer (model related to it) and new_question as property.
-
Decimal number property score with search_result.score value
-
Text property with search_result.text value
-
Document (another model related to the SearchResult model) and chunk_document.id as property.
-
-
Type in the name of the result variable (as new_search_result, for example).
5. Add the prompt AI step after the loop. This one will unite all the previous functions into the most relevant answer. The setting is very similar to other AI steps, you only have to use:
-
A custom prompt for your model. For example, in our use case, it will be the following:
Answer the question using the context. If the context is empty, no relevant documents will be found.
BEGIN QUESTION
END QUESTION
BEGIN CONTEXT
END CONTEXT
-
As for variables, they are:
-
Question with a question value
-
Documents with ai_search value
-
-
For the rest of the options and prompt examples, see the Prompt AI step article.
6. The last step is the Update record. Here you have to:
-
Pick up the new_question as the record variable to update
-
Select the answer property with the answer variable as the value
-
Type in the name for the result variable, e.g. updated_record
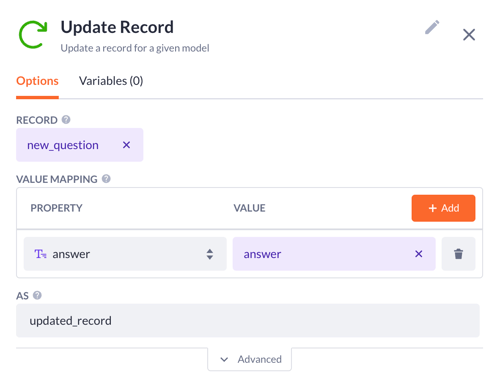
Finally, you have to select the new_question.id as the output variable, and you’re done!
Final check
To wrap this case up, let’s see if everything we’ve set up works in the front end. Return to the main page, Ask a question page in our application, and compile it. Make sure all the model and action permissions are set right.

That’s it! Our application powered by AI action steps works efficiently, giving us the answer compiled from all the chunks that were extracted from Betty Blocks documentation. You can also see the other chunks in the Relevant documents data table.
Overall, the capabilities of AI Search, including Collection search, Query generator, and Chunk actions, can be customized to suit your unique needs and use cases. With the power of natural language processing and text analysis provided by ChatGPT, Betty Blocks builders can now create smart applications that make finding and analyzing information easier and quicker. Good luck!