What is Import CSV/XLS(X) step?
The Import CSV/XLS(X) step does what the name says: it imports CSV or Excel file data to your application. The action step can be found in the Block Store.
You'd typically use it to seed a new app with existing records, migrate data from another system, or let end users upload spreadsheets they maintain elsewhere. The setup has two parts: getting the file accessible by URL, and configuring the action to read and map the data into a model.
The example we'll use
Let's say you're building a client management app, and your sales team has been keeping a list of clients in a spreadsheet. Rather than re-typing every record by hand, you want to pull the file straight into the app.
For this use case, we'll use a CSV file with mock data from mockaroo.com. Feel free to use it too – the columns we created were:
- First_name
- Last_name
- IP_address
You also need a model where each row from the CSV will land. We'll create a model called Client with the same properties as the CSV columns above.

After creating the mock data and the Client model, upload your file to the application using one of the two methods below.
Uploading the file
The Import step needs a file URL to read from. There are two ways to get a file in the right place:
- Public files – the builder uploads the file in the IDE. Fastest path, but only builders have access
- Front-end upload – end users upload the file through a page in the running app. Use this when non-builders need to run imports themselves.
Both paths end the same way: a URL goes into the Import CSV/XLS(X) step. What differs is how the URL gets there.
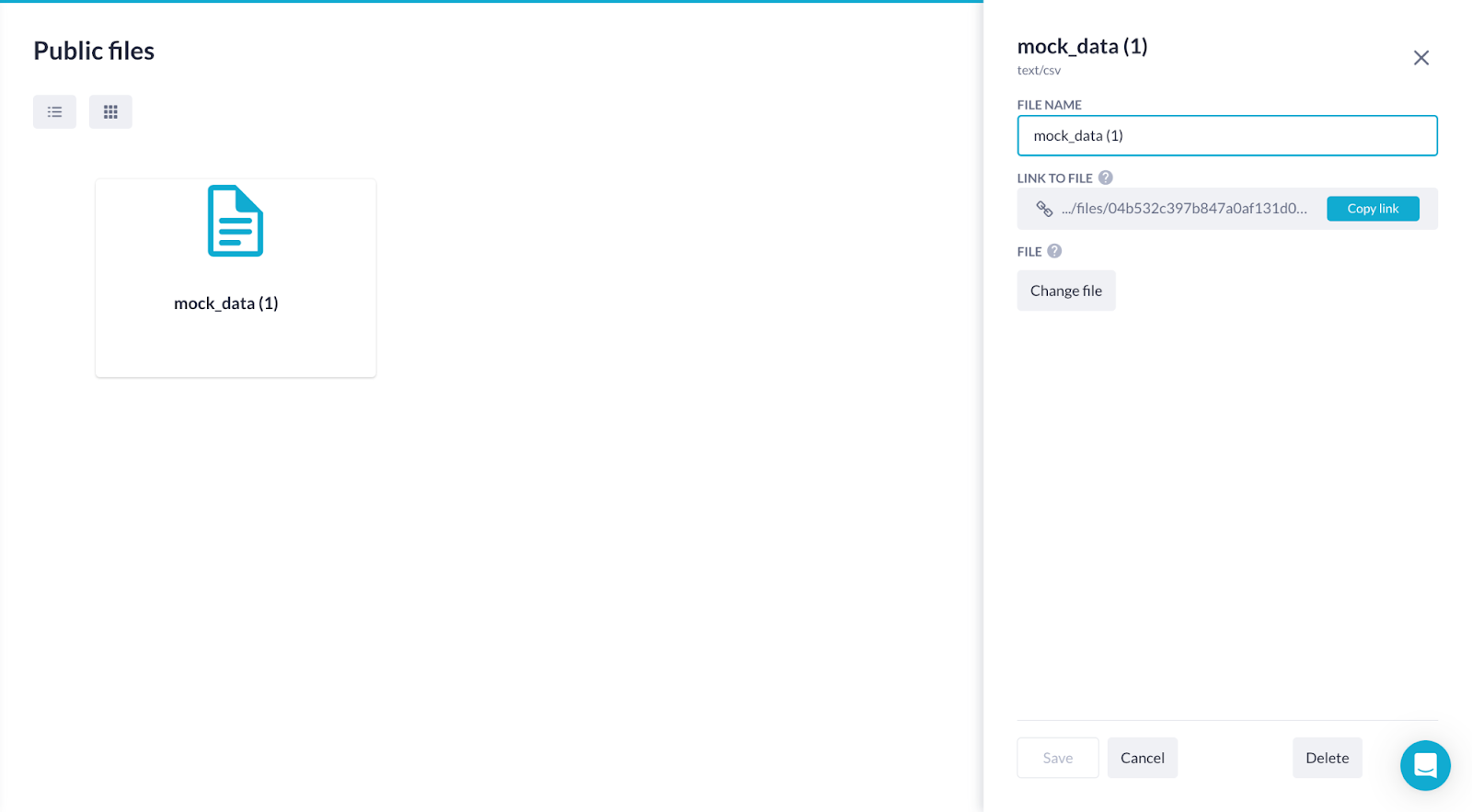
Uploading via public files
Go to the public files page of your application, upload the file, and copy the link. You'll paste this link into the URL field of the Import CSV/XLS(X) action step.
Note: Public files method is the easier route, but only builders with IDE access can use it. If end users need to trigger imports themselves, use the front-end method below.
Uploading files from the front-end
End users don't have access to the IDE, so they need a page where they can pick a file and trigger the import. This setup combines a form, a Сreate Record step, an Expression step, and the Import CSV/XLS(X) step.
The flow:
- The user uploads a file through a File Input on a page
- Create Record step saves the file to a model
- Expression step pulls the URL out of the stored file
- The Import CSV/XLS(X) step uses that URL to run the import
1. Set up an import model
Create a model called Import (or similar) with a File property — call it File. Add other properties or relations later, for example if you want to track who uploaded what.
Set the allowed extensions to csv, xls, xlsx so users can't upload the wrong file type.

2. Build the upload page
Add a page with a Create Form connected to the Import model and drop a File Upload input inside.
.gif?width=670&height=369&name=Screen-Recording-2026-05-07-at-1%20(1).gif)
If you haven't worked with file uploads before, Creating a document upload feature walks through the basics.
3. Add Expression before the import logic
The Form's action already includes a Create Record step. After that step, the record holds the uploaded file – but the Import CSV/XLS(X) step expects a URL string, not a file reference. Add an Expression step in between to resolve it.
Expression step:
- Input:
{{{ file.url }}} -
Add a row in Variables:
- KEY:
file - VALUE: pick the file property of the record created by the Create step (using the (x) variable picker)
- KEY:
- Output type: Text
- Save the result as
file_url.

Import CSV/XLS(X) setup
Now let’s configure your Import CSV/XLS(X) action step. If you’ve uploaded a CSV file via Public files, this is where you begin building your action.
Adding the step
Search "Import CSV" in the Block Store and add the step to your action.

File source and type
-
URL to the import file. Use the
file_urlvariable from the Expression step (front-end method) or paste the public file link directly (public files method). -
Import file type. Pick CSV or Excel (XLS/XLSX) depending on your file. We're using CSV.

Destination model
-
Import model. Select the model where each row will land. For our example, this is
Client.

Mapping
There are three mapping fields. Most setups only need Import mapping.
-
Default mapping (optional) – sets a fixed value on every imported record. Useful when you want to tag every row with metadata. For example, to record which organisation handled the import or to link all import lines to the main import record:
- KEY:
organisation(the property or relation database name) - VALUE:
1(a value, variable, or the ID of a relational record)
- KEY:
-
Import mapping – connects CSV column names to your model's property database names.
- KEY: the CSV column name (exactly as it appears in the import file)
- VALUE: the property database name in snake_case
For our Client model:

-
Format mapping for import columns (only for non-text properties) – text fields work out of the box. You only need entries here for checkbox, decimal, number, or date/time columns.
- KEY: the CSV column name
- VALUE: one of
checkbox,decimal,number,Date,Time, orDatetime
For date-based columns, also specify the format using date-fns notation, e.g. Date, dd-MM-yyyy or Datetime, MM/dd/yyyy H:mm. If a date column doesn't have a format mapping, it won't import correctly.

Deduplication and updates
By default, every row in the CSV creates a new record. If you want re-imports to update existing records instead of duplicating them, configure these options.
-
Deduplicate records (update records if matched). Turn on to let the import update existing records when a match is found. Heads up: this has a performance impact — turn on batched processing too if you're importing more than a few thousand rows.
-
Unique record identifier. The CSV column name used to match existing records. Must be one of the columns you mapped in Import mapping. Pick something genuinely unique like
Email— notFirst_name. -
Unique record type. The data type of the unique column: ID, Text, Number, or Decimal.

-
Update import mapping for existing records (optional) — different mapping logic for updates vs creates. Leave empty unless you specifically want updates to map columns differently from new records. The Import mapping above is used as the default.
Batch options
For huge imports (thousands of rows), single runs may not finish within the platform's action time limit. Batched processing splits the work into chunks and tracks progress.
Turn on batched processing to enable. Once on, configure:
- Model to store batch size and current offset – a model dedicated to tracking import progress.
- Property for batch size – a Number property on that model.
- Batch size – number of records per batch. Default 1000, max 5000.
- Property for offset – a Number property to track current position in the dataset.
- Property for file name – a Text property to uniquely identify this import run.
For small CSVs (like our mock data), skip this section.
Logging and result
Turn on logging for this step. When on, system logs show information like the number of processed records and time taken. Useful while testing; turn off for production.
Result. A required Text variable. The output looks like records created: 4, records updated: 0.

Advanced: validate required columns
When set to true, the import checks that specific columns are present in the file before running. Mark required columns by adding * after the name in the KEY field of Import mapping — for example, First_name*. The import fails fast if a required column is missing.
Run action
Now test the use case by running the action. Uploading and clicking the Send button you created earlier will save the CSV data into your application.
To make the outcome visible right away, you’ll also add a Data Table that displays the records in the model you set up (in this example, the Client model).

To see the result instantly, we will add the following interaction to the Create Form:
OnActionSucess > Refetch > DataTable

After you’ve added the interaction to your button, compile the page. Once the page is compiled, see the updated results – the client records are now displayed in the table.

You’ve now imported your CSV data into the application and learned how to use the Import CSV step to populate your models. For a more in-depth and technical breakdown of this action step, please refer to the GitHub repository. here.
To see our article on exporting CSV files from data models, please visit this article.